NHANES is designed to be representative of the civilian, non-institutionalized population of the United States. NHANES excludes all persons in supervised care or custody in institutional settings, all active-duty military personnel, active-duty family members living overseas, and any other U.S. citizens residing outside the 50 states and the District of Columbia. Non-institutional group quarters (such as college and university residence halls) are included in the survey. See the NHANES Survey Methods and Analytic Guidelines for more details.
NHANES Sampling Procedure
The NHANES sampling procedure consists of four stages, shown and described below.
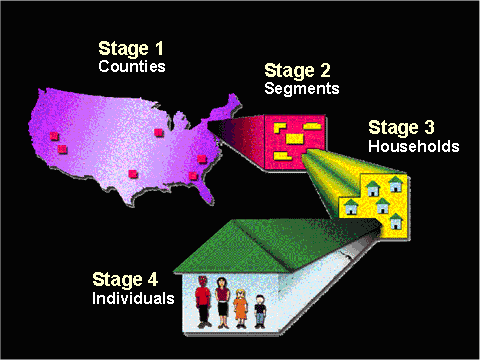
Four Stages of NHANES Sampling Procedure
-
Stage 1: Primary sampling units (PSUs) are selected. These are mostly single counties or, in a few cases, groups of contiguous counties. PSUs are selected with probability proportional to a measure of size (PPS). PPS sampling means that sampling units with larger populations are more likely to be selected than those with smaller populations. For NHANES, the "measure of size" (MOS) used for PPS is a weighted average of population counts, where the weights are calculated to give relatively higher probability of selection to PSUs with higher proportions of individuals within the demographic subgroups chosen for oversampling.
Some PSU ("certainty PSUs") have an MOS large enough that they are selected into the sample with probability = 1. The remaining non-certainty PSUs are partitioned into mutually-exclusive groups, and PSUs are selected from each stratum. Stratification is used to increase the precision of survey estimates for subpopulations important to the survey's objectives.
- Stage 2: The sampled PSUs are divided up into segments (generally city blocks or their equivalent). As with each PSU, sample segments are selected with PPS.
- Stage 3: Dwelling units or households within each segment are listed, and a sample is randomly drawn. In geographic areas where the population has a greater proportion of a particular age, race and Hispanic origin, or income group selected for oversampling, the probability of selection for those groups is greater than in other areas.
- Stage 4: Individuals are chosen to participate in NHANES from a list of all persons residing in selected households. Individuals are drawn at random within designated age-sex-race/Hispanic origin screening subdomains. On average, about 2 sampled persons are selected per eligible household.
Although this general description of the four-stage sampling procedure applies to all cycles of Continuous NHANES, some details of the sample design have changed over time. Detailed technical information can be found in the Sample Design documents, available on the NHANES Survey Methods and Analytic Guidelines page.
The sample is designed so that each annual sample is nationally representative. However, statistical estimates from single-year data are relatively unstable (have large variance estimates) since NHANES can only visit a small number of locations each year due to the time and cost involved in moving the mobile examination centers (MECs) between locations. Therefore, data are publicly released in two-year cycles. However, data from any one NHANES cycle may not be sufficient for certain analysis, such as those that examine subsamples or outcomes with low prevalence. For this reason, combining cycles into samples of four years or more is recommended whenever possible. See the Analytic Guidelines for more information (e.g., page 13 of Vital and Health Statistics, Series 2, Number 190).
What is a Sample Weight?
A sample weight is assigned to each sampled person. It is a measure of the number of people in the population represented by that sampled person in NHANES, reflecting the unequal probability of selection, an adjustment for sampled person non-response, and adjustment to account for differences between the final sample and the total population based on independent population control totals. When unequal selection probability is applied, as in the Continuous NHANES samples, the sample weights are used to produce an unbiased national estimate. More information about sample weights and how they are created can be found in the Weighting module of the tutorial and in the Estimation and Weighting Procedures documentation.
Oversampling
NHANES is designed to sample larger numbers of certain subgroups of particular public health interest. Oversampling is done to increase the number of individuals in the sample in particular subgroups and therefore increase the reliability and precision of estimates of health status indicators for these population subgroups. Since people in oversampled groups have a higher probability of being selected, sample weights adjust for oversampling to obtain national estimates that reflect the true relative proportions of these groups in the U.S. population as a whole.
Oversampling has varied over survey cycles. For example, survey cycles prior to 2007-2008 oversampled Mexican American persons rather than all Hispanic persons. The oversample of non-Hispanic Asian persons began in the 2011-2012 survey cycle. In August 2021-August 2023, there was no oversampling by race and Hispanic origin to minimize in-person interactions during the COVDI-19 pandemic. In future surveys, different subgroups may be oversampled depending on public health trends.
Because oversampling has varied, it is important to consult documentation and analytic guidance to determine how to calculate and present trend estimates for subgroups. A brief description of the oversampled subgroups can be found on the overview page for each survey cycle (e.g. NHANES 2011-2012 Overview.) For more details, consult the Analytic Guidelines and the Sample Design documents on the NHANES Survey Methods and Analytic Guidelines page. For a description of the oversampling domains in the surveys back to the NHANES I (1971–1974), see the National Health and Nutrition Examination Survey: Sample Design, 2011–2014 report, "Table A. Selected sample design parameters: Health and Nutrition Examination Surveys, 1971–2014"
WARNING
For your own analyses, it is critical to carefully review the documentation for each survey cycle to determine which subgroups were oversampled. Sample sizes may be too small to provide reliable nationally-representative estimates for subgroups that were not oversampled in a particular survey cycle.
For example, NCHS recommends that researchers not calculate estimates for all Hispanic persons for survey periods prior to 2007 or for Hispanic subgroups other than Mexican American in any survey cycle. It is also recommended to exercise caution when presenting estimates by race and Hispanic origin for the August 2021-August 2023 cycle because no oversampling by race and Hispanic origin was conducted during that cycle. See the Brief Overview of Sample Design, Nonresponse Bias Assessment, and Analytic Guidelines for NHANES August 2021-August 2023 for additional information.
Strata, PSUs, and Masked Variance Units
NHANES visited 12 PSUs in 1999 and 15 PSUs in each year since 2000. In the first stage, these PSUs were selected from strata defined by geography (e.g. census region), metropolitan statistical area status, and various population demographics. Two PSUs were selected from most strata. Together, these strata and the PSUs represent the variance units (sampling units used to estimate sampling error).
Statistical software procedures used to analyze complex survey data need information about the first stage sampling procedure (i.e. the strata and PSU) to properly estimate the variance.
However, to protect the confidentiality of information provided by survey participants and to reduce disclosure risks, the "true" design strata and PSUs are not released on the public-use data files. Instead, masked variance units (MVUs) for strata and PSUs are constructed for public release. MVUs are equivalent to Pseudo-PSUs used to estimate sampling errors in past NHANES. They produce variance estimates that closely approximate the variances that would have been estimated using the "true" design variables. MVUs have been created in a way that allows them to be used for any combination of data cycles without recoding by the user. The variable name for the masked variance unit pseudo-stratum is sdmvstra and the variable name for the masked variance unit pseudo-PSU is sdmvstra.
Please refer to the Analytic Guidelines for more information on sampling and masked variance units.
See the Variance Estimation module for more information about variance estimation and an overview of how to specify sampling design parameters in some common statistical packages.